Agentic MLLMs
Large language models (LLMs) have advanced dramatically, enabling sophisticated reasoning in natural language. One way to leverage LLMs is to use them in an agentic manner. An agent autonomously accomplishes a given task by using available tools, for example by decomposing the task into finer-grained subtasks and invoking the tools required for each subtask, such as APIs, to ultimately complete the original task. In our laboratory, we are conducting research on incorporating the idea of agents to make LLM outputs more explainable and to enable more advanced reasoning.
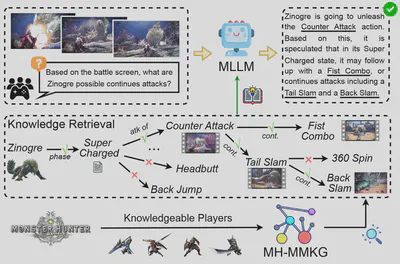
Graph Exploration and Reasoning by Multimodal LLMs for Answering Unknown Problems
The true value of knowledge lies not merely in its accumulation, but in its potential to be effectively utilized to conquer the unknown. Although recent multimodal large language models (MLLMs) have demonstrated impressive multimodal capabilities, they often fail on rarely encountered domain-specific tasks due to limited relevant knowledge. To investigate this issue, this study adopts visual game cognition as a testbed and constructs a multimodal knowledge graph (MH-MMKG) for Monster Hunter: World, incorporating multiple modalities and complex entity relationships. In addition, we design a series of challenging queries based on MH-MMKG to evaluate the models’ ability in complex knowledge retrieval and reasoning. Furthermore, we propose a multi-agent retriever that enables the model to autonomously search for relevant knowledge without requiring additional training. Experimental results show that our method significantly improves the performance of MLLMs, offering a new perspective on multimodal knowledge-augmented reasoning and laying a solid foundation for future research.
The code is available here.
A Dataset for Evaluating the Reasoning Ability of LLMs in the Medical Domain
In recent years, LLMs have demonstrated remarkable capabilities across a wide range of tasks and applications, including those in the medical domain. Models such as GPT-4 excel at medical question answering, but when dealing with complex challenges in real clinical settings, the lack of interpretability can become a critical issue. In this study, we introduce DiReCT, a diagnostic reasoning dataset for clinical notes, with the aim of evaluating the reasoning ability and interpretability of LLMs in comparison with human physicians. DiReCT contains 511 clinical notes, each carefully annotated by physicians with detailed descriptions of the diagnostic reasoning process, from findings in the clinical notes to the final diagnosis. In addition, a diagnostic knowledge graph is provided to supply important knowledge required for reasoning that may not be included in the training data of existing LLMs. Evaluation of major LLMs on DiReCT reveals a substantial gap between the reasoning abilities of these models and those of human physicians, strongly highlighting the need for models that can reason effectively in real-world clinical settings.
The code is available here.