Quantification and mitigation of AI bias
Neural networks have achieved extremely high performance across a wide range of tasks. At the same time, part of this high performance is often attributed to the use of “spurious correlations.” A spurious correlation refers, for example, to an image classification task that includes the class “horse,” where many images containing horses are photographed in grasslands, creating a strong correlation between grasslands and the class label “horse” (that is, images labeled as horses often also contain grasslands). In other words, neural networks may confuse grasslands with horses. This may not seem like a serious problem when the issue is horse versus grassland, but when such correlations involve human attributes such as gender or race, they become what is known as societal bias, which is a major concern. In our laboratory, we are conducting research on societal bias as well as on neural networks and spurious correlations more broadly.
Annotation-Free Mitigation of Societal Bias in CLIP
Large-scale vision-language models such as CLIP are known to contain societal bias regarding human attributes such as gender and age. This paper aims to address the problem of societal bias in CLIP. Prior studies have proposed methods to mitigate societal bias through adversarial learning or test-time projection. However, this paper comprehensively examines those approaches and identifies two limitations: (1) when attribute information is explicitly disclosed in the input, that information may also be lost, and (2) attribute annotations are required during the debiasing process. To overcome these limitations simultaneously while mitigating societal bias in CLIP, this paper proposes SANER (societal attribute neutralizer), a simple yet effective debiasing method. SANER removes attribute information from CLIP text features only for attribute-neutral descriptions. Experimental results show that SANER, which does not require attribute annotations and preserves the original information for attribute-specific descriptions, achieves better debiasing performance than existing methods.

Mitigating Societal Bias in Image Captioning
This study aims to mitigate gender bias in image captioning models. Prior work has addressed this problem by encouraging models to focus on people in order to reduce gender misclassification. However, in exchange for predicting the correct gender, such approaches tended to generate stereotypical gender-related words. This study assumes that there are two types of gender bias affecting image captioning models: (1) bias that leads the model to predict gender from contextual cues, and (2) bias that makes certain words, often stereotypical ones, more likely to be generated depending on gender. To mitigate both types of gender bias, this study proposes a framework called LIBRA. By learning from artificially biased samples, LIBRA reduces both forms of bias, corrects gender misclassification, and replaces gender-stereotypical expressions with more neutral ones.
The code and paper are available here.

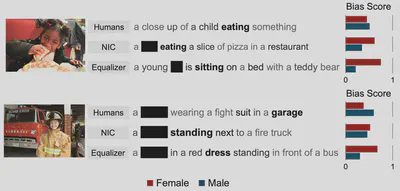
Quantifying Societal Bias in Image Captioning
Image captioning models have been shown to amplify biases related to gender and race, yet there is no standardized metric for measuring, quantifying, and evaluating societal bias in captions. To address this issue, this study provides a comprehensive analysis of the strengths and limitations of existing metrics and proposes LIC as a metric for examining bias amplification in image captioning. Furthermore, in image captioning, it is not sufficient to focus only on whether protected attributes are predicted correctly; the entire context must also be taken into account. Through extensive evaluation of conventional methods and state-of-the-art image captioning models, the study reveals that when attention is paid only to the prediction of protected attributes, models intended to mitigate bias can unexpectedly amplify bias instead.