Explainable AI
Neural networks, including large language models, are sometimes criticized for their black-box nature. The black-box nature of neural networks refers to the fact that the internal mechanisms of the model, from input to output, are not clearly understood. Although neural networks perform an enormous number of computations, there are simply too many of them for us to know what each one represents. As a result, it is difficult to clarify what is happening between the input and the output. In applications such as the medical domain, where the output may lead to serious risks, it is particularly important to be able to explain why a certain decision was made. Explainable AI is a research field that aims, in particular, to reveal the internal mechanisms of neural networks. In our laboratory, rather than relying on the long-dominant post hoc approach (i.e., adding explanations after the neural network has already been trained), we are conducting research on methods that endow neural networks themselves with interpretability during training.
An Explainable Classifier that Automatically Identifies Concepts
Interpreting and explaining the behavior of deep neural networks is critically important for many tasks. Explainable AI provides a way to address this challenge, mainly by explaining decisions in terms of how much each pixel contributes to the final prediction. However, interpreting such explanations may require expert knowledge. In recent years, some studies have adopted concept-based frameworks to improve interpretability by providing higher-level relationships between certain concepts and model decisions. In this paper, we propose the Bottleneck Concept Learner (BotCL). BotCL represents an image solely by the presence or absence of concepts learned through training on the target task, without relying on explicit supervision for those concepts. In addition, by using self-supervised learning and dedicated regularization terms, the learned concepts are encouraged to be understandable to humans. Using image classification tasks as the experimental setting, we demonstrate the potential of BotCL to reconstruct neural networks into a more interpretable form.
The code is available here.
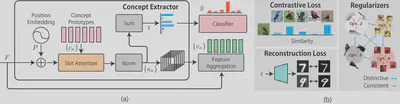
An Explainable Classifier Based on Slot Attention
Many existing methods in explainable AI are based on gradients or intermediate features, which are not directly involved in the classifier’s decision-making process. In this paper, we propose SCOUTER, a slot attention-based classifier that achieves both transparency and high classification accuracy. There are two major differences from other attention-based methods: (a) SCOUTER’s explanations directly contribute to the final confidence score of each category, enabling more intuitive interpretation; and (b) for every category, corresponding positive or negative explanations are provided. This makes it possible to show not only why an image belongs to a certain category, but also why it does not belong to another category. Furthermore, we design a new loss function for SCOUTER, which allows switching between positive and negative explanations and controlling the size of the explanation regions. Experimental results show that SCOUTER provides better visual explanations across various evaluation metrics while maintaining high accuracy on small- and medium-scale datasets.
The code and related materials are available here.
