大規模モデルの応用
大規模言語モデル(LLM)の飛躍的な発達は、自然言語での高度な推論を可能にしました。LLMを活用するための一つの方法として、LLMをエージェント的に使う方法が考えられています。エージェントとは、与えられたツール等を使って自律的に与えられたタスクをこなすもので、例えばタスクをより細かいサブタスクに分解して、それぞれのサブタスクに必要なツール(APIなど)を呼び出すなどによって最終的に元のタスクを実現します。当研究室では、エージェントの考え方を取り入れることで、LLMの出力に説明可能性を持たせたり、より高度な推論を可能にするための研究を進めています。
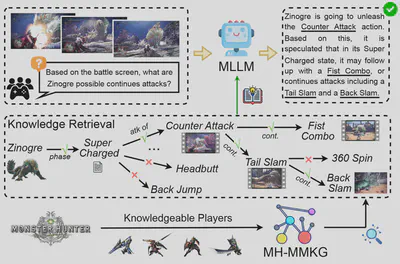
未知の問題に回答するためのマルチモーダルLLMによるグラフの探索と推論
知識の真の価値は、単に蓄積されることにあるのではなく、それを効果的に活用して未知のものを克服できる可能性にあります。近年のマルチモーダル大規模言語モデル(MLLM)は優れたマルチモーダル能力を示しているものの、関連知識が限られているため、まれにしか遭遇しない特定領域のタスクではしばしば失敗します。この点を検証するために、本研究では視覚的ゲーム認知を実験基盤として採用し、「Monster Hunter: World」を対象に、複数のモダリティと複雑なエンティティ関係を取り入れたマルチモーダル知識グラフ(MH-MMKG)を構築します。また、MH-MMKGに基づく一連の挑戦的なクエリを設計し、複雑な知識検索および推論に対するモデルの能力を評価します。さらに、追加学習を必要とせず、モデルが自律的に関連知識を探索できるマルチエージェント検索器を提案します。実験結果は、我々の手法がMLLMの性能を大幅に向上させることを示しており、マルチモーダル知識拡張推論に新たな視点を与えるとともに、今後の研究のための堅固な基盤を築くものです。
コードはこちら。
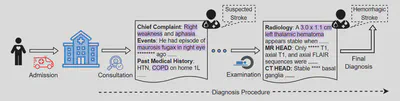
LLMの医療分野における推論能力評価のためのデータセット
LLMは近年、医療分野を含む幅広いタスクや応用において、顕著な能力を示しています。GPT-4のようなモデルは医療質問応答に優れていますが、実際の臨床現場における複雑な課題を扱う際には、解釈可能性の不足が課題となる場合があります。そこで本研究では、臨床ノートを対象とした診断推論データセット DiReCT を導入し、LLMの推論能力および解釈可能性を人間の医師と比較して評価することを目的とします。DiReCTには511件の臨床ノートが含まれており、それぞれについて医師が注意深くアノテーションを行い、臨床ノート中の所見から最終診断に至るまでの診断推論過程を詳細に記述しています。さらに、既存のLLMの学習データには含まれていない可能性のある、推論に必要な重要知識を提供するために、診断知識グラフも用意されています。主要なLLMをDiReCT上で評価した結果、これらのモデルの推論能力と人間の医師の推論能力との間には大きな隔たりがあることが明らかとなり、実世界の臨床場面で効果的に推論できるモデルの必要性が強く示されています。
コードはこちら。