AIのバイアスとその低減
ニューラルネットワークはさまざまなタスクで極めて高い性能を達成しています。一方で、この高性能さの一部は「表層的相関」を利用しているとも言われています。表層的相関とは、例えば「ウマ」というクラスを含む画像分類問題で、ウマがいる画像はだいたい草原で撮影されていることから、草原とクラスラベルとしての「ウマ」の間にも高い相関があることになります(ウマのラベルがついてる画像には、大抵草原も写っている)。つまり、ニューラルネットワークは、草原とウマを混同してしまうのです。ウマと草原であればそれほど問題ないかもしれませんが、これがジェンダーや人種などの人の属性に関わってくると、社会的バイアスと呼ばれ、大きな問題になります。当研究室では、社会的バイアスをはじめ、ニューラルネットワークと表層的バイスに関する研究を進めています。
CLIPのためのアノテーションフリーの社会的バイアス低減
CLIPのような大規模視覚言語モデルには、人の属性(例えば、性別や年齢)に関する社会的バイアスが含まれていることが知られています。本論文は、CLIPにおける社会的バイアスの問題に取り組むことを目的としています。従来研究では、敵対的学習やテスト時の射影によって社会的バイアスを低減する手法が提案されてきましたが、本論文ではそれらを包括的に検討し、1) 属性情報が入力中で明示的に開示されている場合に、その情報まで失われてしまうこと、2) バイアス低減の過程で属性アノテーションを必要とすること、の二点の限界を明らかにしました。これらの限界を同時に克服しつつ、CLIPにおける社会的バイアスを軽減するために、本論文では、SANER(societal attribute neutralizer)と呼ばれる、単純でありながら効果的なバイアス低減手法を提案します。SANERは、属性に中立な記述に対してのみ、CLIPのテキスト特徴から属性情報を除去する手法です。実験結果より、属性アノテーションを必要とせず、かつ属性に特有な記述については元の情報を保持できるSANERは、既存手法よりも優れたバイアス低減性能を示すことが分かりました。

画像キャプション生成のための社会的バイアス低減
本研究では、画像キャプション生成モデルにおけるこのようなジェンダーバイアスの軽減を目的とします。従来研究では、性別の誤分類を減らすために、人に注目するようモデルを誘導することでこの問題に対処してきました。しかしその一方で、正しい性別を予測することと引き換えに、ジェンダーに関するステレオタイプ的な語を生成してしまう傾向がありました。画像キャプション生成モデルに影響するジェンダーバイアスには、次の2種類があると本研究では仮定します。すなわち、1) 文脈を利用して性別を予測してしまうバイアス、2) 性別によって特定の(しばしばステレオタイプ的な)語が生成されやすくなるバイアス、の2つです。これら両方のジェンダーバイアスを軽減するために、本研究ではLIBRAと呼ばれる枠組みを提案します。LIBRAは、人工的にバイアスを付与したサンプルから学習することで、両方のバイアスを低減し、性別の誤分類を是正するとともに、ジェンダーに関してステレオタイプ的な語をより中立的な表現へと置き換えます。
コードと論文はこちらから。

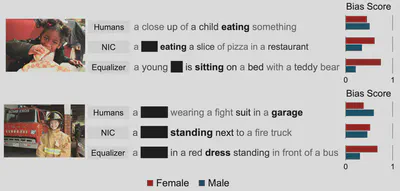
画像キャプション生成における社会的バイアスの定量化
画像キャプション生成モデルは、ジェンダーや人種に関するバイアスを助長しうることが示されていますが、キャプション中の社会的バイアスを測定・定量化・評価するための指標は標準化されていません。そこで本研究では、各指標の長所と限界を包括的に分析するとともに、キャプション生成におけるバイアス増幅を検討するための指標としてLICを提案します。さらに、画像キャプション生成においては、保護属性を正しく予測できているかだけに注目するのでは不十分であり、文脈全体を考慮する必要があります。従来手法および最先端の画像キャプション生成モデルに対して大規模な評価を行った結果、保護属性の予測のみに注目した場合、バイアス低減を目的としたモデルが、かえって予想外にバイアスを増幅していることが明らかになりました。